汉字的前端字体体积优化方案
对于欧洲等基于字母文字的地区,字体优化简单,大小通常不超过 1MB。但对于东亚国家,字体尺寸是一个头疼的问题,可能会达到数兆字节甚至更多。
对于欧洲等基于字母文字的地区来讲,字体优化是一件很简单的事情,字体大小一般不超过 1MB。但是对于亚洲尤其是东亚中国港澳台及日韩来讲,字体尺寸是一件非常令人头疼的问题。在前端项目中,字体文件可能动辄上几个单位的兆字节甚至更多。
举个例子,以西班牙语的 Cantina Fresca 字体来讲,TTF 格式的字体大小仅为 300KB,并且打包成 WOFF2 格式后可以优化到 200KB 的大小,对于一个前端页面来讲,甚至还没有一张位图的体积大,加载字体的速度和时间均在可接受的范围内,并不是问题。
但是,对汉字不尽如此。汉字的基本单位 —— 偏旁部首不像字母文字一样可以随意拼接组合,而是必须以字为单位具体设计。根据中国的汉字分类法,一类汉字和二类汉字数量中常用的汉字数量大约在 4000 左右。再加上汉字的字体矢量图形也比字母文字复杂得多,所以一个包括常用汉字的字体文件大小至少在 2MB 以上,是字母字体的五到六倍。
如果字体文件太大,对于前端来讲则是很大的负担。过大的字体文件不仅会严重拖延加载速度,而且字体可能会导致页面排版布局的改变而触发浏览器重排(reflow)机制,降低渲染性能。
做成图片
在早期的网页,若想使用艺术字体,那么其中一种方法,就是用专业的设计软件如 PhotoShop 把字体用在图片素材上,或者生成背景透明的文字图片再用到网页上。这种办法一般只用于展示页、落地页。

需要用什么字体,提前设计做成图片上,虽然有效,但如今看来这是一种笨办法。因为落地页是需求变化频率非常高的场合,如果需求变更,要求修改文字内容,亦或者是调整大小、颜色,那么还需要重头开始制作字体图片,从 UI 组到前端就必须重新干活,效率低下。
如果可以,我们换一种改进方法:制作字库。提前把所有的字符都抽出来做成矢量图片,需要的时候可以从字库中选取指定的图片即可。现在这种方法还常见于某些网站的落地页、展示页。
子集化
做成图片的方式效率太低,那么有没有办法改进办法呢?其中一个方法就是字体子集化(Subsetize)。字体文件是按照编码来给每个文字分别储存字形的。
根据中国大陆的文字分类工作方案,字表共收字 8105 个,其中一级字表(常用字集)3500 个,二级字表 3000 个。而一类字和二类字中有 4000 左右的常用汉字,就可以覆盖 90% 以上的文献资料。对于商业网站来讲,这些字量完全够用了。
而大多数字体也通常会给生僻字编码。像康熙字典体具有很高的美学价值,完整版收录了 10 万左右的汉字,体积大小也达到了惊人的 70 MB,而其中 99% 以上都是生僻字。这些生僻字我们不需要,把它裁剪去就行了。在 Github 上有很多相关的工具,如 FontSmaller,这是一个在线子集化工具,还有Fontmin 等。我自己也收集总结了一些常用的汉字、符号等,可以用于字体子集化时挑选出指定的目标字体,用于参考。
被裁减后的康熙字典体体积可以缩减成 5MB。
对于静态生成式网页也可以更激进一点:由于生成的文字内容是相对固定的,那么每次生成网页时,可以先读取出网页上都有哪些字符,然后再从字体中挑选对应字符的字体,然后生成字体的子集。
例如 PHP 的 php-font-lib 库、Webpack 构建系统的插件Fontmin-Webpack。但是这样的方案适合静态生成式网页,对于动态网页则灵活性非常差,也不能很好处理用户输入的问题。
Web Open Font Format
子集化的方案虽然能裁剪去很多不必要的字符,但是优化空间仍然有限。而对于 TTF,OTF 这类字体格式,那么能否寻找一种方式,能大限度地压缩字体文件大小?
后来,Mozilla 与 Type Supply、LettError 及其他组织于 2009 年协同开发了一种新的网页字体格式 WOFF(Web Open Font Format,Web 开放字体格式)。它使用了与 TrueType、OpenType、Open Font 所采用的 sfnt 结构类似的压缩算法。
WOFF 本质上是包含了基于 sfnt 的字体(如 TrueType、OpenType 或开放字体格式),且这些字体均经过 WOFF 的编码工具压缩,以便嵌入网页中。这个字体格式使用 zlib 压缩,文件大小一般比 TTF 小 40%。
后来对 WOFF 格式上再做一些改进,又开发了 WOFF2 格式。WOFF 2 标准在 WOFF1 的基础上,进一步优化了体积压缩,带宽需求更少,同时可以在移动设备上快速解压。
与 WOFF 1.0 中使用的 Flate 压缩相比,WOFF 2.0 是使用 Brotli 方法进行的压缩,压缩率更高,所以文件体积更小。
在 Github 上也提供了字体转换为 WOFF 的相关工具。而且很多的专业字体转换网站如Convert.io都提供字体转换功能
借助这种优化方案,我们就可以把子集化的字体在此基础上,继续优化到原大小的 40% 左右。例如我这个博客,正文使用的是思源屏显臻宋,由原来的 13.8MB 的 TTF 文件优化到现在的 2.5MB 左右。
但尽管如此,浏览器在加载超过 1MB 的字体时,性能非常差用 lighthouse 测评得分也很难超过 60。
Font Spilt
根据统计,打开一个网站时,用户能接受的加载时间为 7 秒左右。 超过这个时间,用户就会丧失兴趣。以现代的网络条件下,不包括浏览器渲染过程,以带宽速度 0.5MBPS 下,想要在 7 秒内加载完一个网页,就意味着加载网站数据,包括静态资源、网页内容等大小一般在 2-3MB 左右。
但是中文字体再怎么优化也很难优化成 1MB 以下,中文字体大小在加载数据中仍然是个大头。这显然在用户体验上也不符合要求。
那么还有没有别的方案呢?或许,我们可以让字体按需加载。思路是:把一个完整的字体按照字符范围,拆分成十几个甚至几十上百个小字体。加载网页时,在网页上找出有哪些字符,然后再加载对应收录范围的小字体文件。
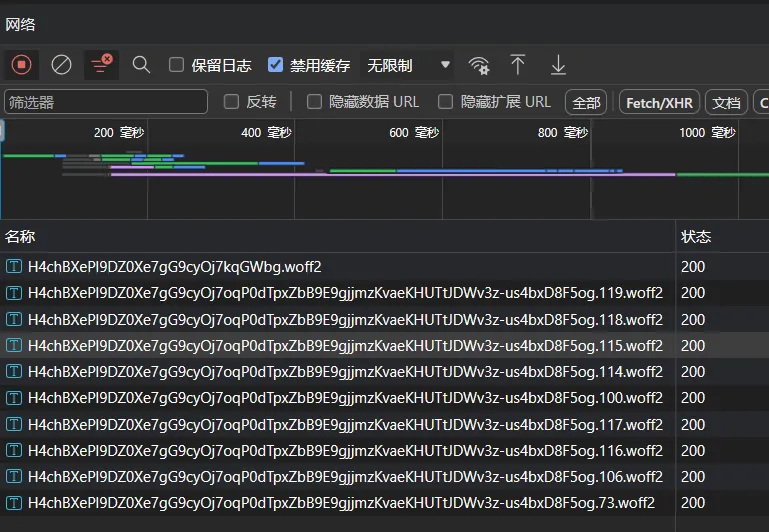
这也是 Google Fonts 的优化方案。
由此一来,就有望把字体加载大小降到 1MB 以下。这项方案需要 CSS 的支持。在 CSS 中有一个非常重要的规则:unicode-range。
The unicode-range CSS descriptor sets the specific range of characters to be used from a font defined using the @font-face at-rule and made available for use on the current page. If the page doesn't use any character in this range, the font is not downloaded; if it uses at least one, the whole font is downloaded.
简单来说,就是在使用 @font-face 定义字体时,它允许你指定 unicode-range 来标注应用字体的文字 Unicode 编码范围。
@font-face {
font-family: "source-serif";
src: url("./source-serif.woff2") format("woff2");
unicode-range: U+e240-e34f;
}
例如以上代码,这一行指定了应使用此字体的 Unicode 范围。在这个例子中,它只会对从 U+E240 到 U+E34F 的范围这一区间内的文字应用字体。假如文字不在 U+e240-e34f 这个编码范围内,那么就不会加载 source-serif 这个字体。
Google Font 就遵循了这个思路,通常针对中文字体把文字编码拆分成 100kb 左右的大量小字体文件,然后再生成对应的 CSS 规则代码,实现字体按需加载。
有了这个 CSS 特征,那么我们就可以很好地进一步优化了。首先第一步就是 Font-spilt,为字符范围编码,生成大量的、体积小的子字体,第二步是为编码范围和字体碎片生成指定的 CSS 规则文件。
这样就可以把每次加载字体的数据控制到 1MB,甚至 500KB 以下。就大大节省了加载数据量。


在 Github 上已有对这类方案的成熟实现,并且提供了在线的 Font-Spilt 工具,进行字体分包。
在此之前,开源界对中文字体的优化方案很少,感谢 @江夏尧 的 中文网字计划,提供了这个优秀的项目。
不尽如此,中文网字计划还托管了很好看的中文字体,可以开箱使用。也欢迎各位为这个项目提供更好看的中文字体。